2022. 12. 21. 21:09ㆍ기술 공부/알고리즘
오늘은 최댓값( 또는 최솟값)을 찾는 알고리즘과
중복되는 값을 찾는 알고리즘을 알아보자.
최댓값( 또는 최솟값)을 찾는 알고리즘을 알아보기 위해,
우선 숫자들이 담긴 List를 하나 준비하자.
(예시를 위해 중복되지 않는 숫자들을 담았다.)
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13]
이 List에서 최댓값을 구하는 방법은 무엇이 있을까.
아무래도 가장 빠르게 떠오른 방법은
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13]
max_num = 0
for num in nums:
if num > max_num:
max_num = num
print(max_num)출력 결과 :
99이 될 것이다.
위 방법은 nums List에 담긴 모든 숫자를 하나하나 비교하므로
nums List에 담긴 숫자가 많아 질 수록, 비례하여 연산 시간이 늘어날 것이다.
따라서 '빅 오' 표기법에 따르면, O(n)이 될 것이다.
하지만, 역시 우리는 도구를 다루는 인간으로서 Python을 적극적으로 이용해야 한다.
그리고 이 경우에는, Max라는 내장 함수를 사용하면 손 쉽게 해결된다.
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13]
print(max(nums))출력 결과 :
99???
그렇다. 적극적으로 Python의 내장 함수를 탐색해보자. 유용한 내장 함수가 많다.
중요한 게 하나가 더 있는데, 이 경우 내장 함수를 적용하지 않으면, O(n) 이지만,
내장 함수 Max 를 사용하면 그 보다 더 빠르다.
Python 내부에서 Max 내장 함수가 어떻게 작동하는 지 아직 발견하지 못했지만, 미스테리다.
반대로 최솟값의 경우,
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13]
print(min(nums))출력 결과 :
2내장 함수 Min을 사용하면 될 것이다.
Python 만만세
다음으로 중복되는 값을 찾는 알고리즘을 알아보자.
마찬가지로, 중복되는 값이 담긴 List를 하나 만든다.
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13, 10]
이 List에서 중복값을 찾는 방법은 무엇이 있을까.
음.. 일단 생각나는 대로 적어보자.
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13, 10]
duplicate = set()
for x in range(len(nums)):
for y in range(x + 1, len(nums)):
if nums[x] == nums[y]:
duplicate.add(nums[x])
print(duplicate)결과 출력 :
{10}
그림으로 바꿔보자면,
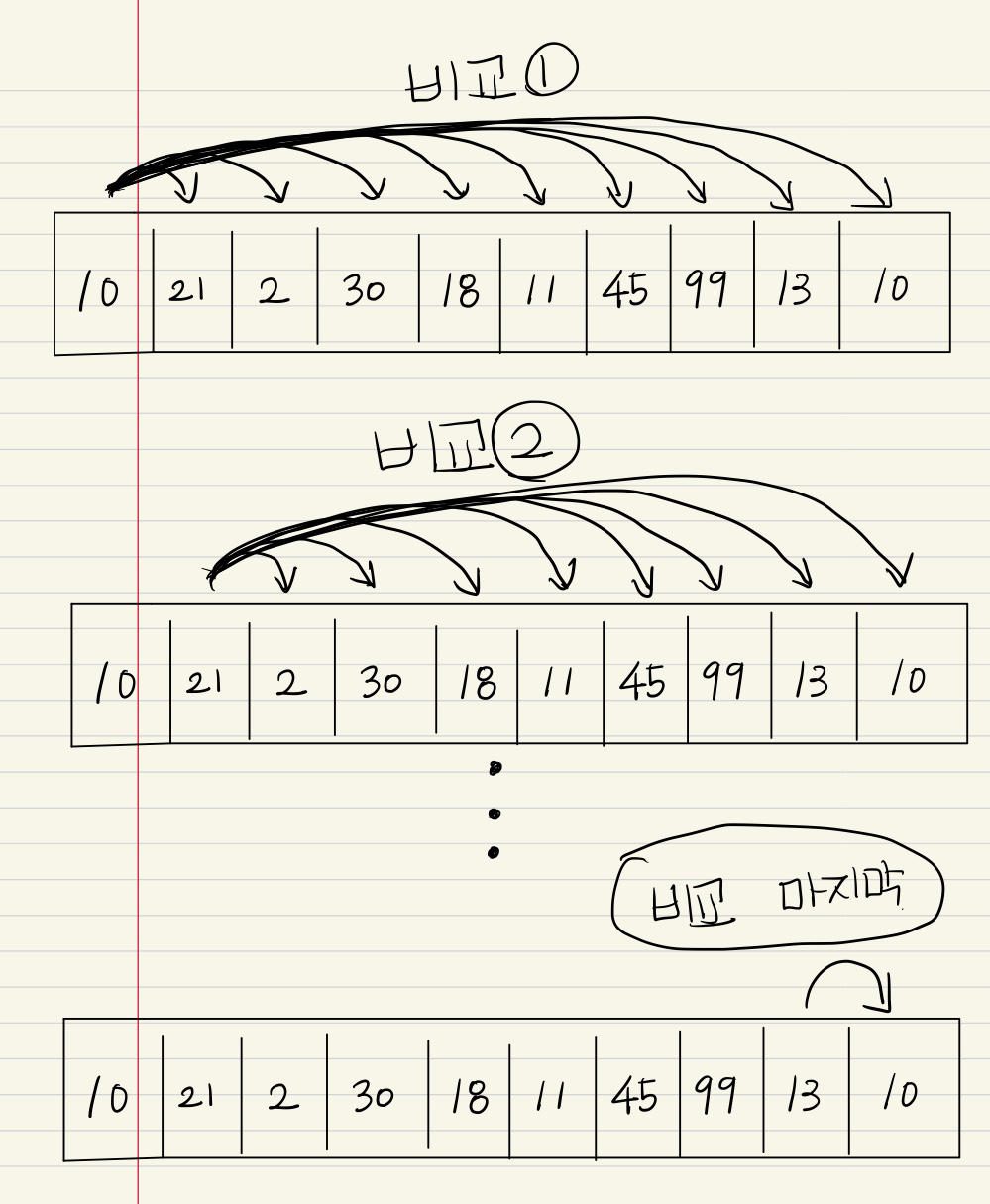
이렇게 흘러간다는 코드이다.
그렇다면 비교 횟수는 ...
비교 ① 은 9번,
비교 ② 는 8번,
....
비교 마지막은 1번이 될 것이다.
한마디로 List 길이보다 1작은 숫자부터 1까지의 총 합이라고 볼 수 있다.
Python에게 계산을 맡겨보자.
print(sum(range(10)))출력 결과 :
45
적어도 최댓값을 구할 때는 숫자의 수 만큼씩 늘어났지만,
이 경우에는 좀 도가 지나쳤다.
이런 경우를 빅 오 표기법에서는 O(n^2) (n 의 제곱) 이라고 부르기로 했다.
이 처럼 연산 시간이 굉장하게 증가당해버리기 때문에
대부분의 경우 코드를 짜면서 2중, 다중 For를 피할 수 있으면 피하라는 이야기가 많은 것이다.
자, 그럼 우리는 어떻게 해야할까.
이번에는 Python에서 어떤 내장 함수를 써야하는 걸까.
1차 시도로 List의 Count 함수를 이용해보자.
import time
# 2중 For문을 이용한 중복 값 찾아내기
st = time.time()
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13, 10]
duplicate = set()
for x in range(len(nums)):
for y in range(x + 1, len(nums)):
if nums[x] == nums[y]:
duplicate.add(nums[x])
print(duplicate)
print(f'{time.time() - st:.10f} sec')
print()
# List Count를 이용한 중복 값 찾아내기
st = time.time()
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13, 10]
duplicate = set()
for x in nums:
if nums.count(x) > 1:
duplicate.add(x)
print(duplicate)
print(f'{time.time() - st:.10f} sec')출력 결과 :
{10}
0.0000338554 sec
{10}
0.0000109673 sec호오. 나름 선방한것 같다.
2차 시도로 Collections 라이브러리의 Counter 함수를 써보자.
import time
# 2중 For문을 이용한 중복 값 찾아내기
st = time.time()
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13, 10]
duplicate = set()
for x in range(len(nums)):
for y in range(x + 1, len(nums)):
if nums[x] == nums[y]:
duplicate.add(nums[x])
print(duplicate)
print(f'{time.time() - st:.10f} sec')
print()
# List Count를 이용한 중복 값 찾아내기
st = time.time()
nums = [10, 21, 2, 30, 18, 11, 45, 99, 13, 10]
duplicate = set()
for x in nums:
if nums.count(x) > 1:
duplicate.add(x)
print(duplicate)
print(f'{time.time() - st:.10f} sec')
# Collections Counter 함수를 이용한 중복 값 찾아내기
from collections import Counter
st = time.time()
nums = Counter([10, 21, 2, 30, 18, 11, 45, 99, 13, 10])
duplicate = set()
for k in nums:
if nums[k] > 1:
duplicate.add(k)
print(duplicate)
print(f'{time.time() - st:.10f} sec')출력 결과 :
{10}
0.0000350475 sec
{10}
0.0000119209 sec
{10}
0.0000448227 sec호오. 생각치도 못한 결과다.
숫자의 개수가 적어서 그런 걸까.
적당히 10000개 정도로 해보자.
import time
import random
nums = random.choices(range(1, 1000001), k=10000)
st = time.time()
duplicate = set()
for x in range(len(nums)):
for y in range(x + 1, len(nums)):
if nums[x] == nums[y]:
duplicate.add(nums[x])
print(duplicate)
print(f'{time.time() - st:.10f} sec')
print()
st = time.time()
duplicate = set()
for x in nums:
if nums.count(x) > 1:
duplicate.add(x)
print(duplicate)
print(f'{time.time() - st:.10f} sec')
print()
from collections import Counter
st = time.time()
nums2 = Counter(nums)
duplicate = set()
for k in nums2:
if nums2[k] > 1:
duplicate.add(k)
print(duplicate)
print(f'{time.time() - st:.10f} sec')출력 결과 :
{685187, 455684, 597511, 303118, 9743, 370321, 497940, 52118, 808471, 742936, 980121, 458906, 43036, 629021, 464545, 560420, 693925, 25381, 756141, 436783, 744624, 579132, 54081, 245061, 180039, 549963, 74189, 788435, 976853, 410966, 807004, 624606, 259295, 489194, 458478, 298222, 871667, 620407, 692344, 662779, 960764, 995198}
7.2956371307 sec
{685187, 455684, 597511, 303118, 9743, 370321, 497940, 52118, 808471, 742936, 980121, 458906, 43036, 629021, 464545, 560420, 693925, 25381, 756141, 436783, 744624, 579132, 54081, 245061, 180039, 549963, 74189, 788435, 976853, 410966, 807004, 624606, 259295, 489194, 458478, 298222, 871667, 620407, 692344, 662779, 960764, 995198}
1.3691072464 sec
{685187, 455684, 597511, 303118, 9743, 370321, 497940, 52118, 808471, 742936, 980121, 458906, 43036, 629021, 464545, 560420, 693925, 25381, 756141, 436783, 744624, 579132, 54081, 245061, 180039, 549963, 74189, 788435, 976853, 410966, 807004, 624606, 259295, 489194, 458478, 298222, 871667, 620407, 692344, 662779, 960764, 995198}
0.0017180443 sec호오. 유의미한 결과다.
압도적인 차이로 Collections Counter 의 승리다.
역시 인간은 도구를 써야한다.
정리하자면, O(n^2)의 성능을 가졌던 알고리즘을
Python의 내장 함수들을 이용하여 더 빠르게 처리해보았다. (?)더 이상 알고리즘 공부 글이 아닌거 같은 기분이 들지만
아무튼 Python의 내장 함수들을 유용하게 사용하자.
'기술 공부 > 알고리즘' 카테고리의 다른 글
| 알고리즘, 파이썬을 곁들인 (6) - 삽입 정렬 (0) | 2023.01.04 |
|---|---|
| 알고리즘, 파이썬을 곁들인 (5) - 선택 정렬 (0) | 2023.01.03 |
| 알고리즘, 파이썬을 곁들인 (4) - 순차 탐색 (0) | 2023.01.03 |
| 알고리즘, 파이썬을 곁들인 (3) (0) | 2022.12.21 |
| 알고리즘, 파이썬을 곁들인 (1) (0) | 2022.12.20 |