MySQL - WINDOW Function
이번 시간엔 WINDOW Function에 대한 내용을 정리해 보자.
이번 시간의 목표는 다음과 같다.
- WINDOW Function의 역할.
- WINDOW Function의 사용법.
+ MySQL을 기준으로 작성되었습니다.
+ SQL 코드는 Google Cloud Console의 BigQuery에서 실행되었습니다.
+ thelook_ecommerce 데이터 셋을 사용하였습니다.
+ 이 글은 개인적으로 공부를 위한 글입니다.
WINDOW Function의 역할.
먼저 WINDOW Function이 무엇인지 알아보자.
MySQL Docs(8.0 기준)을 읽어보자.
WINDOW function은 쿼리 행 집합에 대해 집계와 유사한 작업을 수행합니다.
그러나 집계 작업은 쿼리 행을 단일 결과 행으로 그룹화하는 반면 WINDOW function은 각 쿼리 행에 대한 결과를 생성합니다.
음. 한 줄씩 알아보자.
WINDOW Function은 집계 함수(COUNT, SUM, AVG 등등)와 유사한 작업을 진행한다고 한다.
흠. 그렇다면, COUNT, SUM, AVG 등등은 어떠한 작업을 진행하는가.
SELECT
COUNT(id) AS TOTAL_COUNT,
SUM(cost) SUM_COST,
AVG(retail_price) AS AVG_RETAIL_PRICE
FROM
`thelook_ecommerce.products`;
한 데이터 집합에 대한 집계(개수, 총 합, 평균 등등)를 내리는 작업을 한다.
그리고 그 결과를 한 행(ROW) 그룹화하여 결과를 생성한다.
또한 집계 함수와 Column을 동시에 SELECT 할 수 없다.
SELECT
id,
COUNT(id) AS TOTAL_COUNT,
SUM(cost) SUM_COST,
AVG(retail_price) AS AVG_RETAIL_PRICE
FROM
`thelook_ecommerce.products`;
'SELECT 목록 표현식이 [131:3]에서 그룹화되거나 집계되지 않은 열 ID를 참조합니다.'라고 오류가 나온다.
(131: 3은 행 번호, 3번째는 글자 번호이다.)
반면 WINDOW Function은 각 쿼리 행에 대한 결과를 생성한다고 한다.
즉, COUNT, SUM, AVG 등등의 집계 함수를 사용하여도 하나의 행으로 그룹화하여 출력하는 게 아닌,
각 행에 대한 결과(WINDOW, 창)를 생성하여 각 행에 같이 묶는 것이다. 이게 말이 된다니.
예시를 봐보자.
SELECT
id,
COUNT(id) OVER() AS TOTAL_COUNT,
SUM(cost) OVER() AS SUM_COST,
AVG(retail_price) OVER() AS AVG_RETAIL_PRICE
FROM
`thelook_ecommerce.products`
LIMIT 10;
훌륭하다. 솔직히 놀랍다.
내 작은 지식의 안에서 보더라도,
백엔드에서는 전체 집계 값을 가져오는 쿼리, 데이터 리스트를 가져오는 쿼리 2개를 실행시킨 후,
결과 값들을 받아 백엔드, 가끔은 프런트엔드에서 이 두 데이터를 합쳤었다...
(그 예시로 페이지네이션 처리 백엔드 및 쿼리가 있겠다.)
결론부터 이야기해 보자면, 행에 대한 집계와 행에 대한 정보를 동시에 가져올 수 있다..!
그 안에는 행을 그룹화시켜 각 집계 함수에 대한 연산을 통해 새로운 칼럼을 생성하고 그 집계 결과 값을 넣는 과정이 숨어있는 것이다.
쉽게 말하자면 위의 WINDOW Function 쿼리는,
SELECT
id
FROM
`thelook_ecommerce.products`
LIMIT
10000;SELECT
COUNT(id) AS TOTAL_COUNT,
SUM(cost) AS SUM_COST,
AVG(retail_price) AS AVG_RETAIL_PRICE
FROM
`thelook_ecommerce.products`
LIMIT
10000;이 두 쿼리가 동시에 실행되면서 하나의 결과 값으로 합쳐진다는 이야기와 유사하다고 볼 수 있다.
이는 (주관적인 백엔드 기준) 2개의 쿼리를 요청해야 할 것을 1개의 쿼리로 끝낼 수 있고,
곧 리소스(트래픽, DB 연결 세션 등등)를 아낄 수 있다는 것이고 이 것은 곧 서버 비용의 절감으로 이어진다.
잠시 빠르게 산으로 가보자.
백엔드에서 사용한 2개의 쿼리보다는, WINDOW Function의 속도가 느릴 것으로 생각된다.
서비스에서는 처리 시간이 하나의 중요한 요소이기 때문에, WINDOW Function을 사용하지 않았던 것일 수도 있다고 생각한다.
(페이지네이션에는 ROLLUP이 좀 더 어울릴 수 있겠다.)
물론 백엔드 서버와 Read용 데이터베이스의 물리적 거리도 있기 때문에 이는 환경에 따라 다를 것으로 생각한다.
네트워크 통신 시간이 데이터베이스 연산보다 오래 걸리는 경우 WINDOW Function이 효율적일 수도 있겠다.
즉, 2번(집계 함수 SQL, 데이터 리스트 SELECT SQL) 요청과 응답을 주고받는 시간 + 데이터베이스 연산 시간보다,
1번(WINDOW Function) 요청과 응답을 주고받는 시간 + 데이터베이스 연산 시간이 빠르다면 말이다.
아래 비교 내용은 그냥 확인만 하도록 하자.
+ 아래 내용은 별도의 포스팅으로 만들어볼 생각이다. 나도 궁금하기 때문에...
아래는 한 개의 쿼리(WINDOW Function)를 BigQeury에서 실행한 상세 정보이다.
SELECT
id,
COUNT(id) OVER() AS TOTAL_COUNT,
SUM(cost) OVER() AS SUM_COST,
AVG(retail_price) OVER() AS AVG_RETAIL_PRICE
FROM
`thelook_ecommerce.products`
LIMIT
10000;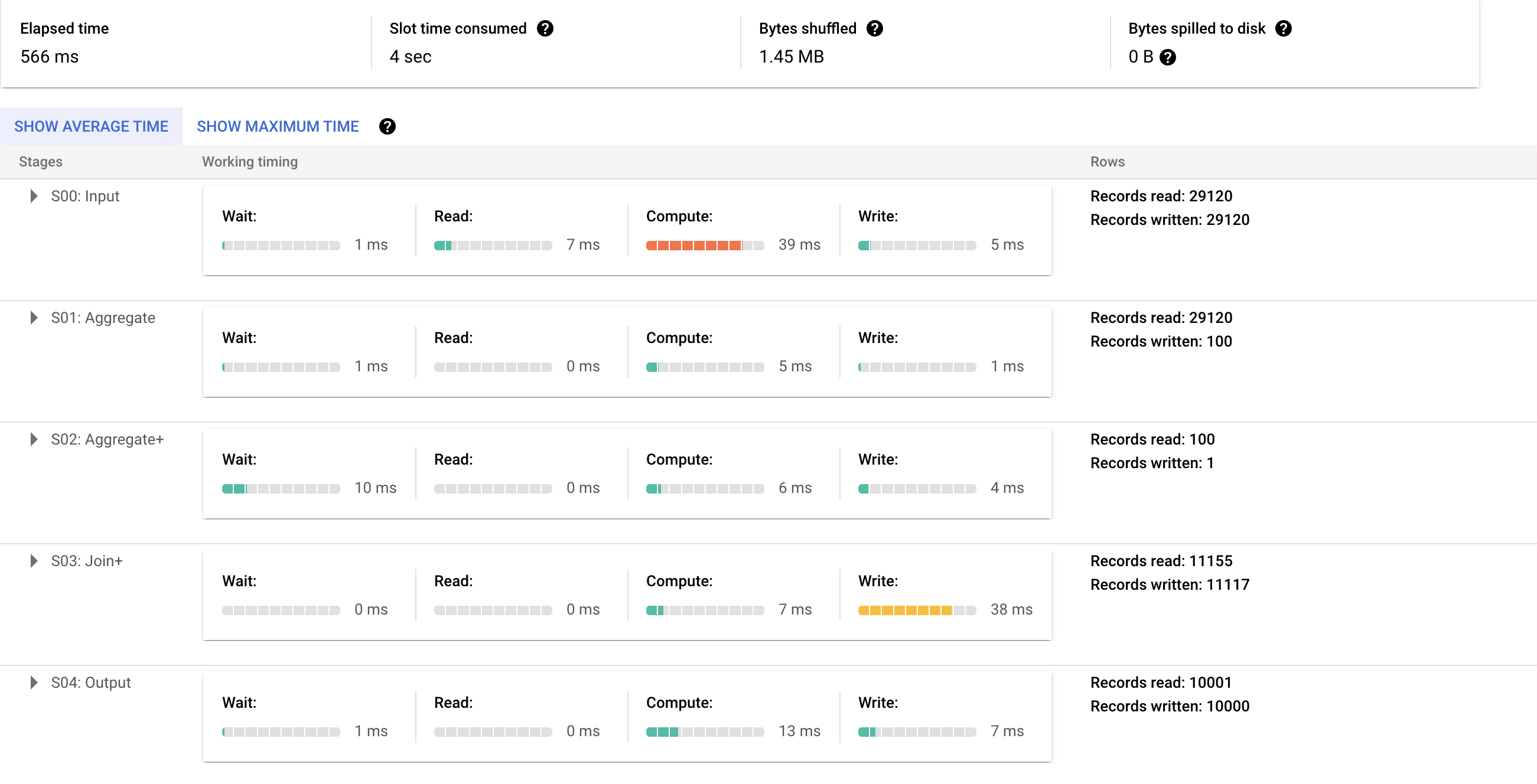
아래는 두 개의 쿼리(SELECT 집계 함수, SELECT id)를 BigQeury에서 실행한 상세 정보이다.
SELECT
COUNT(id) AS TOTAL_COUNT,
SUM(cost) AS SUM_COST,
AVG(retail_price) AS AVG_RETAIL_PRICE
FROM
`thelook_ecommerce.products`
LIMIT
10000;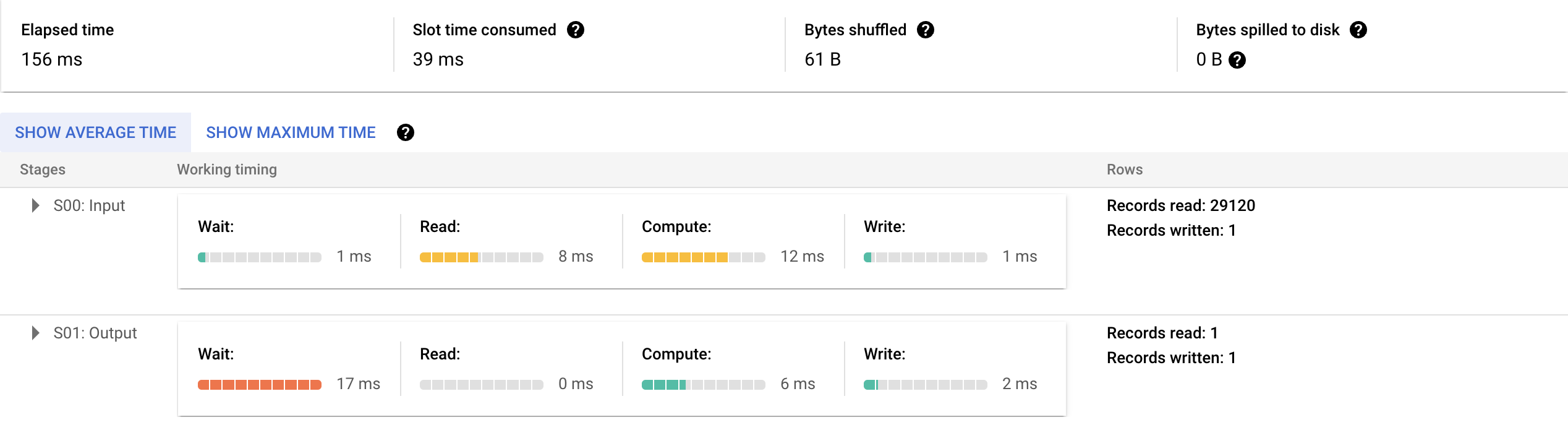
SELECT
id
FROM
`thelook_ecommerce.products`
LIMIT
10000;
참고용이긴 하지만, Elapsed time이 꽤나 흥미로운 결과를 보인다.
WINDOW Function의 경우, 566ms
2 쿼리의 경우, 156 + 185 = 341ms
약 60%의 성능(실행 시간) 차이를 보인다.
이 내용은 나중에 따로 글을 작성하도록 하자.
하산할 시간이다.
+ 네트워크 시간이 필요하지 않은 Local DB에서 실험할 계획이다. 너무 기대된다.
WINDOW Function의 사용법.
앞서 우리는 WINDOW Function이
집계 함수와 함께 사용되어, 그 결과를 행마다 표시를 해주는 것을 확인하였다.
그럼 이 WINDOW Function을 어떻게 하면 더 잘 사용할 수 있을까?
그 방법에 대해 알아보자.
우선 WINDOW Function에는 window_spec을 지정할 수 있다.
window_spec에는 3가지가 존재한다.
- Partition_clause:
- GROUP BY처럼 행을 나누는 그룹(Partition, 파티션)을 지정한다. 지정하지 않는다면, 모든 행을 하나의 파티션으로 지정한다.
- Order_clause:
- 파티션 내에 정렬 기준을 지정한다. 지정하지 않는다면, 파티션 내의 행의 순서가 지정되지 않습니다.
- Frame_clause:
- Frame(프레임)은 현재 파티션의 하위 집합이며, 이런 하위 집합을 정의하는 방법을 지정한다.
- 여기서는 ROWS, CURRENT ROW, UNBOUNDED, PRECEDING, FOLLOWING 만 기억하면 된다.
Frame_clause에 대해 추가로 설명해 보자면,
- ROWS: 파티션의 전체 행을 의미한다.
- CURRENT ROW: 현재 행을 의미한다.
- N PRECEDING: N(숫자)행 앞을 의미한다.
- N FOLLOWING: N(숫자)행 뒤를 의미한다.
- UNBOUNDED: 맨 첫 번째 행 또는 맨 마지막 행 번호를 의미한다. 위 PRECEDING, FOLLOING의 N 대신 사용할 수 있다.
Partition_clause, Order_clause, Frame_clause의 예시를 간단하게 봐보자.
SELECT
id,
category,
brand,
retail_price,
AVG(retail_price)
OVER(
PARTITION BY brand
ORDER BY retail_price DESC
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS AVG_PRICE
FROM
`thelook_ecommerce.products`
WHERE
id BETWEEN 1
AND 10
ORDER BY
brand;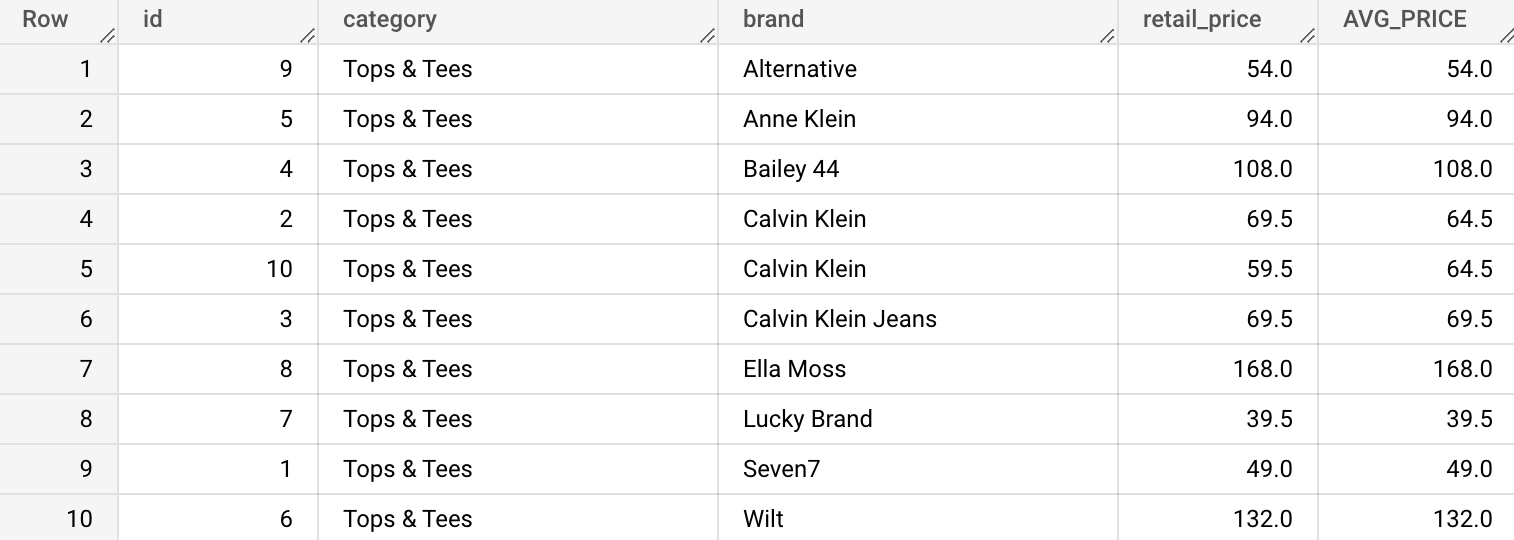
위 예시 쿼리가 어떻게 이 결과물을 조회하는지 까지 과정을 알아보자.
(이해를 돕기 위한 내용이다. 실제 과정은 이와 실제로 다를 수 있다.)
- products 테이블에서 id가 1부터 10까지인 행들을 가져온다.
- id가 1부터 10까지인 행들의 id, category, brand, retail_price를 가져온다.
- 첫 번째 행(1)부터 마지막 행(10)까지의 각 brand의 평균을 구한다.
(가져온 데이터(id가 1부터 10까지인 데이터)를 기준으로 작동하게 된다.)
(Calvin Klein의 AVG_PRICE를 보면, Calvin Klein의 평균값을 볼 수 있다.) - 구해진 brand마다의 평균값을 옆에 붙인다.
- brand로 오름차순으로 정렬한다.
- 각 brand의 retail_price로 정렬한다.
여기서는 맨 처음 행 번호(1)와 맨 끝 행의 번호(10)가 정해져 있으므로
UNBOUNDED 대신 숫자(1과 10)를 넣어준 쿼리도 위와 똑같이 작동한다.
SELECT
id,
category,
brand,
retail_price,
AVG(retail_price)
OVER(
PARTITION BY brand
ORDER BY retail_price DESC
ROWS BETWEEN 1 PRECEDING AND 10 FOLLOWING
) AS AVG_PRICE
FROM
`thelook_ecommerce.products`
WHERE
id BETWEEN 1
AND 10
ORDER BY
brand;
그리고, Frame_clause(ROWS BETWEEN 1 PRECEDING AND 10 FOLLOWING)를 삭제하면,
SELECT
id,
category,
brand,
retail_price,
AVG(retail_price)
OVER(
PARTITION BY brand
ORDER BY retail_price DESC
) AS AVG_PRICE
FROM
`thelook_ecommerce.products`
WHERE
id BETWEEN 1
AND 10
ORDER BY
brand;
무엇이 변했을까.
바로 Calvin Klein의 첫 번째 행의 AVG_PRICE가 69.5로 변하였다.
그 이유는 Frame_clause가 없는 쿼리는 이렇게 작동하기 때문이다.
- products 테이블에서 id가 1부터 10까지인 행들을 가져온다.
- id의 번호가 1부터 시작하여 10까지 반복된다.
- id가 N인 id, category, brand, retail_price를 가져온다.
- brand마다의 각 brand의 평균을 구한다.
- 구해진 brand마다의 평균값을 옆에 붙인다.
- 다음 id 번호로 넘어간다.
- brand로 오름차순으로 정렬한다.
- 각 brand의 retail_price로 정렬한다.
즉, id가 2인 행이 불러와졌을 때는 id가 10인 행을 불러오지 못했다.
Calvin Klein의 평균을 69.5 / 1을 하기 때문에 Calvin Klein의 평균이 그대로 69.5로 조회되었다.
그리고, id가 10인 행을 불러왔을 때는,
id 2번이 불러와져 있기 때문에, (69.5 + 64.5) / 2를 연산하여 Calvin Klein의 평균이 64.5로 나온 모습이다.
(MySQL 기반의 DB의 처리 방식은 기본적으로 순차 처리이기 때문이다.)
이렇게 상황마다의 데이터를 연산하는 모양이 마치 창문(WINDOW)을 통해 보이는 것만 본다라는 의미로
WINDOW라는 이름을 붙여주지 않았을까... 생각해 보았다. 아님 말고.
또한 위에서 알아보았듯이 몇몇 함수와 같이 사용할 수 있다.
AVG()
BIT_AND()
BIT_OR()
BIT_XOR()
COUNT()
JSON_ARRAYAGG()
JSON_OBJECTAGG()
MAX()
MIN()
STDDEV_POP(), STDDEV(), STD()
STDDEV_SAMP()
SUM()
VAR_POP(), VARIANCE()
VAR_SAMP()이 함수들은 WINDOW Function과 함께 사용될 수도 있지만,
WINDOW Function과 별개로도 사용할 수 있다.
아래 함수들은 WINDOW Function이 없으면 사용할 수 없는 함수들이다.
RANK()
DENSE_RANK()
ROW_NUMBER()
LAG()
LEAD()
FIRST_VALUE()
LAST_VALUE()
NTH_VALUE()
NTILE()
PERCENT_RANK()
CUME_DIST()이 함수들은 WINDOW Function이 없으면 사용할 수 없다.
함수들에 대한 설명까지 넣자면 너무 길어지니. 이번 글에서는 넘어가도록 하자.
특히 아래의 WINDOW Function이 없으면 안 되는 함수들은 다른 글에서 또 다뤄볼 예정이다.
(개인적으로 매우 흥미로웠다.)
마무리를 해보자면,
WINDOW Function을 통해, 여러 번에 처리할 쿼리들을 한 번의 쿼리로 처리할 수 있다.
특히, 집계에 관한 연산은 말이다.
WINDOW Function이 실제 서비스를 구현할 때, 많이 사용될지는 의문이다.
하지만, 데이터 분석 - 통계 분야에서는 유용하게 사용될 것 같다.
적어도 나의 작은 지식 안에서는 말이다.
WINDOW Function의 3가지 spec을 지정하여 좀 더 다채로운 집계를 내릴 수 있다.
WINDOW Function과 함께 사용할 수 있는 함수들이 정말 신세계였다.
이 부분은 곧 새로운 글로 만날 예정이다.